Benchmarking¶
We value reproducibility. Our experiments should be reproducible and expected to have similar results when one tries. Therefore, we 1) desrcibe our benchmarking procedure as complete as possible and 2) publish all the code with fair amount of documentation.
If there is any doubt or unclear part, please let us know. We are happy to clarify and improve the document.
Please note here that AttaCut models are denoted as AttaCut-SC and AttaCut-C. The former is AttaCut with syllable and character features, while the latter uses only character feature.
Tokenization Quality¶
Tokenization quality is measured in terms of precision, recall, and f1. We do the measurements in two levels, namely character and word. Figure below describes how these metrics are computed:
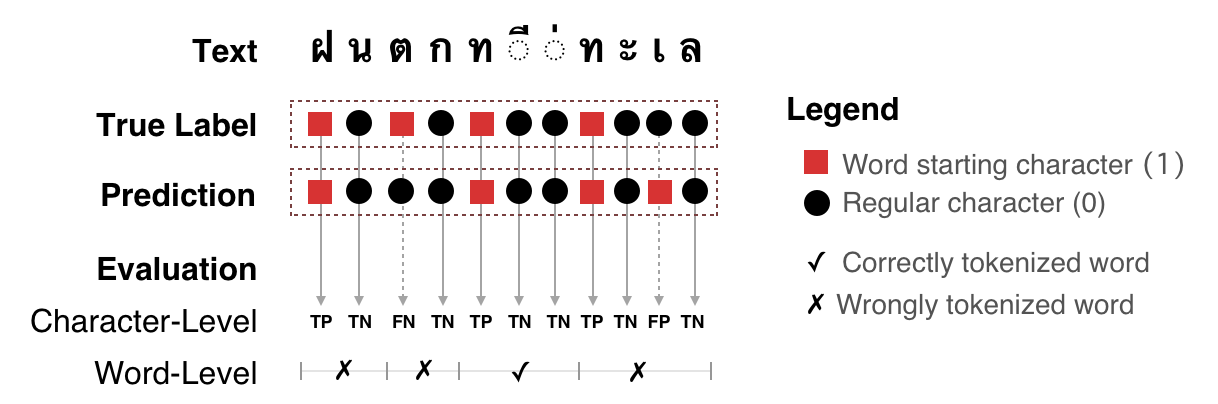
Character- and Word-Level Metrics for Word Tokenization¶
Character-Level:
[P]recision = TP / ( TP + FP )
[R]ecall = TP / ( TP + FN )
f1 = 2PR / (P+R)
Word-Level:
P = #✓ / #◼︎ in prediction
R = #✓ / #◼︎ in text
To increase reproducibility and ease further research, we have developed an evaluation framework for this process. The framework contains two main ingredients:
- Bechmark CLIAt the moment, this CLI can be found at @pythainlp’s tokenization-benchmark, but it will be soon released in the main PyThaiNLP package (version 2.1). Please see it this milestone 1 for recent updates.
- Result Visualization and Comparison WebsiteThis website serves as a tool for error analysis on tokenization results as well as a benchmark collection of other publicly available tokenizers.
Results 3¶
We evaluate tokenization quality on four datasets, namely BEST 4, Orchid 6, 1000 samples from Wisesight Sentiment Corpus 8, and Thai National Historical Corpus (TNHC) 5.
Because we train on BEST, Orchid, Wisesight, and TNHC are out-domain evaluations, testing whether tokenizers are robust.
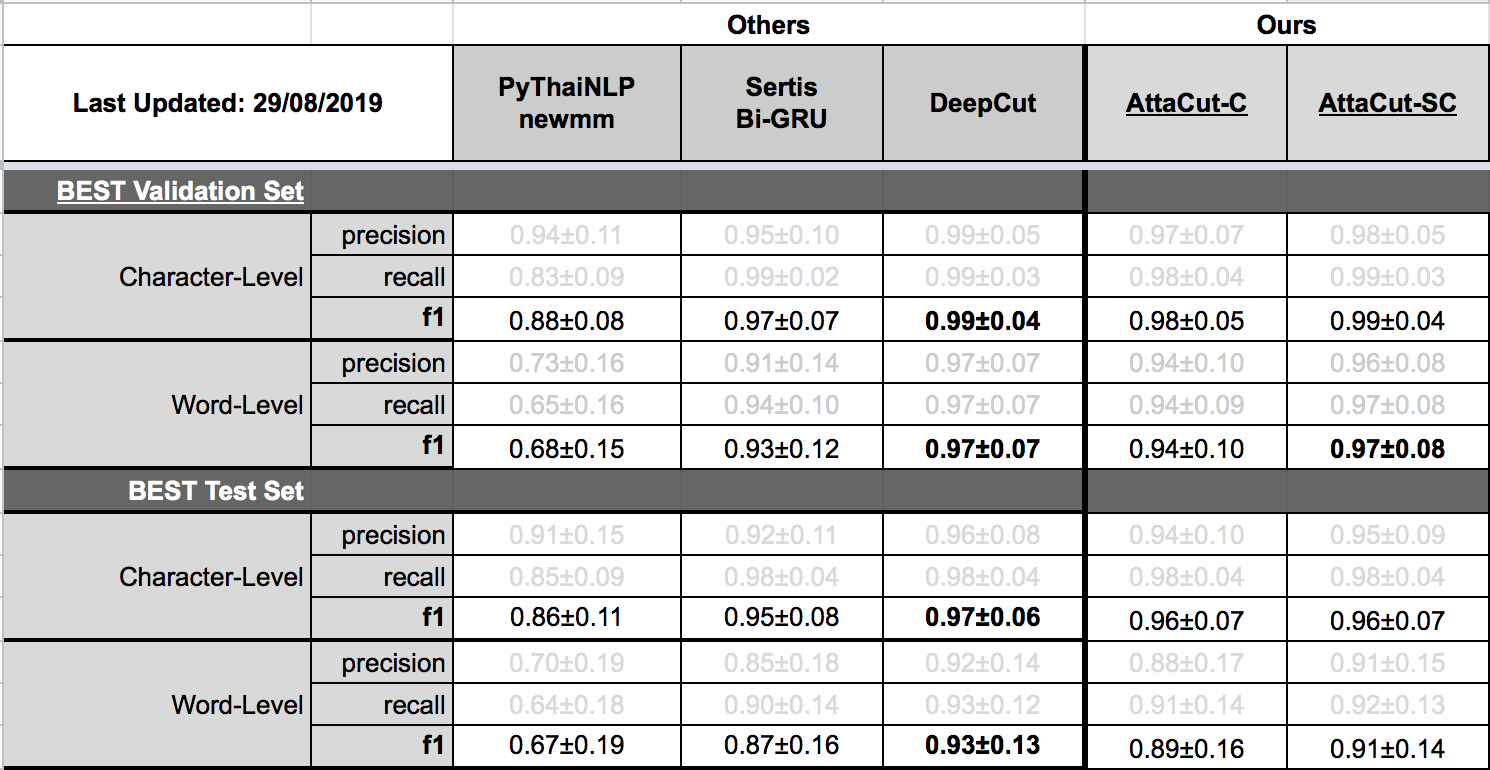
Tokenization Quality on BEST (in-domain)¶
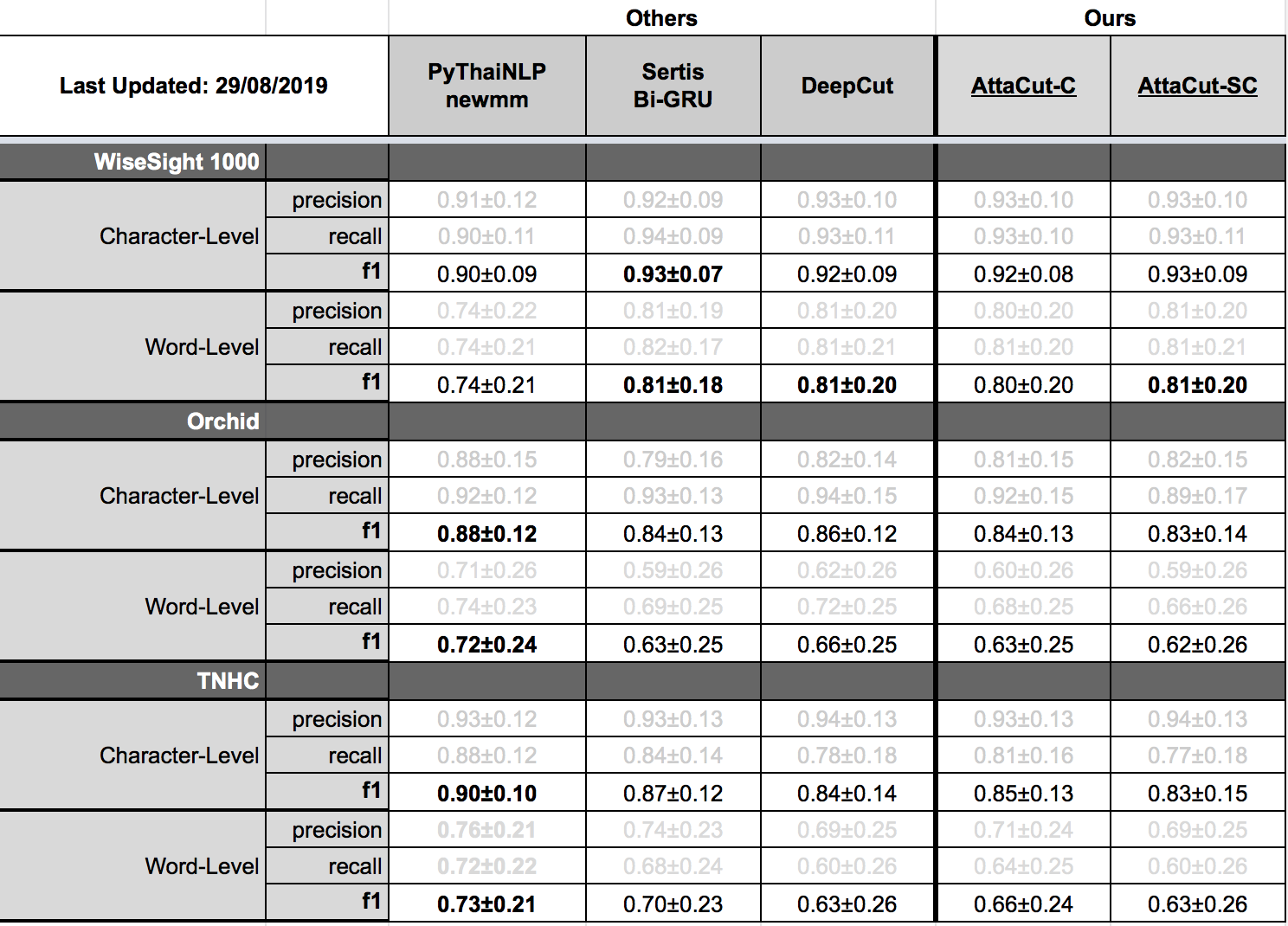
Tokenization Quality on Wisesight, Orchid, and TNHC (out-domain)¶
For in-domain evaluations, AttaCut-SC’s quality is quite similar to DeepCut only two percentage different on BEST’s test set. On the other hand, ML-based tokenizers are on par on Wisesight 1000-sample set. Interestingly, on Orchid and TNHC, PyThaiNLP’s newmm is the best. The reason might be that these two datasets use a different tokenization standard than BEST.
Speed¶
Our speed benchmarking is done on standardized environments, namely Google Colab and AWS’s EC2 instances (t2.small & t2.medium).
Benchmarking on Google Colab¶
Due to Google Colab’s accessibilty and convenience, we use Google Colab for our early speed benchmarking. In this experiment, we vary the length of input text and measure the speed of tokenizers. From the figure below, we can see that our AttaCut models are significantly faster than DeepCut.
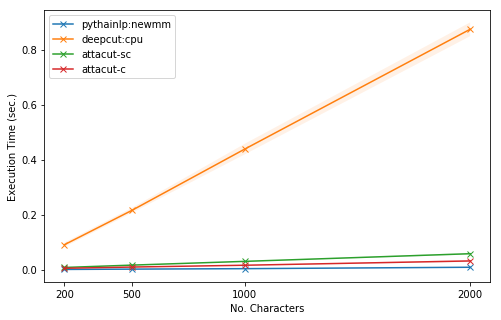
Tokenization Time of PyThaiNLP’s newmm, DeepCut, and AttaCut on Google Colab¶
Benchmarking on EC2 Instances¶
Practically, tokenization is part of NLP pipelines that is usually done on cloud instances, such as AWS EC2, due to scalibility and cost efficiency. Typically, these instances contain a couple of CPU cores and memory, posing another challenge to services, i.e. tokenization, executued there.
Evaluating tokenizer’s speed on such an instance allows us to get realistic results and yet reproducible. We use the training set of Wisesight Sentiment Corpus 7 as a input dataset. The corpus contains texts from social media and online forum platforms. The training set has around 24,000 lines and about 1.5M characters.
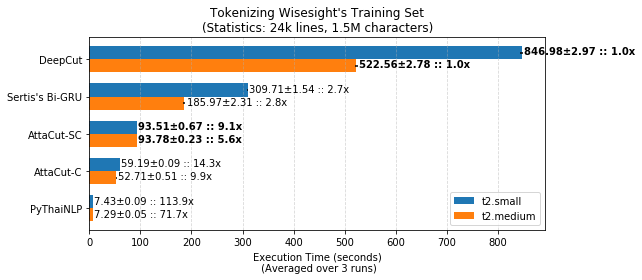
Wisesight’s Training Set Tokenization Time of PyThaiNLP’s newmm, DeepCut, and AttaCut on AWS Instances.¶
From the figure above, AttaCut models are fasters than other existing ML-based tokenizers. More precisely, AttaCut-SC (our best model) is aroud 6x faster than DeepCut, the current state of the art word tokenizer for Thai, while having a similar level of tokenization quality.
- 1
- 2
- 3
P. Chormai. Tokenization Quality Benchmark SpreadSheet, 2019
- 4
NECTEC. BEST: Benchmark for Enhancing the Standard of Thai language processing, 2010.
- 5
J. Sawatphol and A. Rutherford. TNHC: Thai National Historical Corpus, 2019.
- 6
V. Sornlertlamvanich et al. ORCHID: Thai Part-Of-Speech Tagged Corpus, 2009
- 7
- 8
PyThaiNLP. 1000 Samples from Wisesight-Sentiment Corpus, 2019