pythainlp.benchmarks¶
The pythainlp.benchmarks contains utility functions for benchmarking
tasked related to Thai NLP. At the moment, we have only for word tokenization.
Other tasks will be added soon.
Modules¶
Tokenization¶
Quality¶
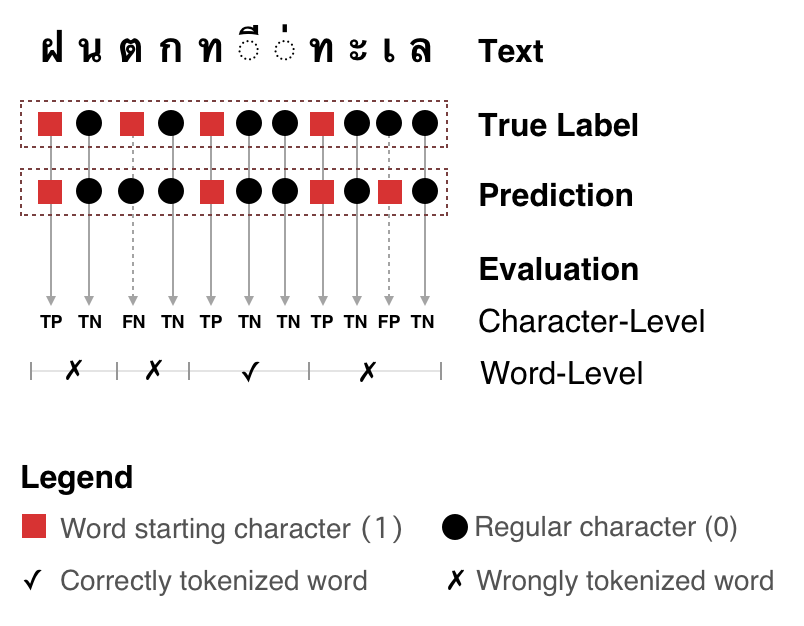
Qualitative evaluation of word tokenization.¶
-
pythainlp.benchmarks.word_tokenization.compute_stats(ref_sample: str, raw_sample: str) → dict[source]¶ Compute statistics for tokenization quality
These statistics includes:
- Character-Level:
True Positive, False Positive, True Negative, False Negative, Precision, Recall, and f1
- Word-Level:
Precision, Recall, and f1
- Other:
Correct tokenization indicator: {0, 1} sequence indicating the correspoding word is tokenized correctly.
-
pythainlp.benchmarks.word_tokenization.benchmark(ref_samples: List[str], samples: List[str]) → pandas.core.frame.DataFrame[source]¶ Performace benchmark of samples.
Please see
pythainlp.benchmarks.word_tokenization.compute_stats()for metrics being computed.