AttaCut: A Fast and Accurate Neural Thai Word Segmenter¶



![]()


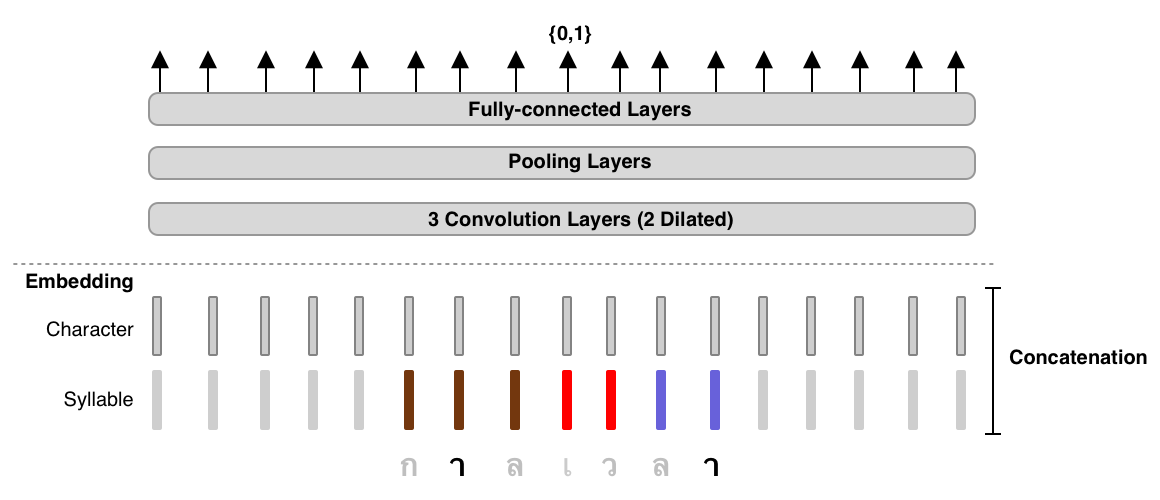
TL;DR: 3-Layer Dilated CNN on syllable and character features. It’s 6x faster than DeepCut (SOTA) while its WL-f1 on BEST 1 is 91%, only 2% lower.¶
Installatation¶
pip install attacut
Note: For Windows Users, please install torch before running the command above. Visit PyTorch.org for further instruction.
Usage¶
Command-Line Interface¶
$ attacut-cli -h
AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai
Usage:
attacut-cli <src> [--dest=<dest>] [--model=<model>] [--num-cores=<num-cores>] [--batch-size=<batch-size>] [--gpu]
attacut-cli [-v | --version]
attacut-cli [-h | --help]
Arguments:
<src> Path to input text file to be tokenized
Options:
-h --help Show this screen.
--model=<model> Model to be used [default: attacut-sc].
--dest=<dest> If not specified, it'll be <src>-tokenized-by-<model>.txt
-v --version Show version
--num-cores=<num-cores> Use multiple-core processing [default: 0]
--batch-size=<batch-size> Batch size [default: 20]
High-Level API¶
from attacut import tokenize, Tokenizer
# tokenize `txt` using our best model `attacut-sc`
words = tokenize(txt)
# alternatively, an AttaCut tokenizer might be instantiated directly,
# allowing one to specify whether to use attacut-sc or attacut-c.
atta = Tokenizer(model="attacut-sc")
words = atta.tokenize(txt)
AttaCut will be soon integrated into PyThaiNLP’s ecosystem. Please see PyThaiNLP #28 for recent updates
For better efficiency, we recommend using attacut-cli. Please consult our Google Colab tutorial for more detials.
- 1
NECTEC. BEST: Benchmark for Enhancing the Standard of Thai language processing, 2010.